The Process to Build a Federated Learning Model in Synergos
One of the main goals of Synergos is to make Federated Learning accessible and user-friendly. To use Synergos to build federated models, users just need to supply necessary meta-data about the compute resources and data they are using. With the input of those meta-data, different components of Synergos then do the heavy lifting to enable Federated Learning.
In this chapter, we will talk about how users interact with Synergos and what happens in the background to enable Federated Learning.
Users of Synergos
The key benefit of Federated Learning is that different parties (we will use the term party and user interchangeably) can collaboratively train a machine learning model without exposing their data to one another. They interact with Synergos in different manners, based on their roles.
There are two main types of users in Synergos.
- One type of user is called the participant. Participants contribute data, so that others can benefit from the data they contribute, while not exposing their data directly to others.
- Another type of user is called the orchestrator. They do not contribute data. Rather, they are responsible in coordinating other participants to complete Federated Learning, e.g. they start the federated training and decide when to stop the training.
Three phases of users' interaction with Synergos
There are three phases of users' interaction with Synergos, namely Registration, Training, and Evaluation.
In the Registration phase, all the parties (including orchestrator and participants) declare necessary meta-data, e.g., network connection information, data contributed by participants, etc. Orchestrators and participants need to provide different categories of information, which will be covered in later sections of this chapter.
In the Training phase, with the meta-data collected in the Registration phase, different components in Synergos work together to complete the federated training. In this phase, the orchestrators will trigger the start of federated training process. Besides this, no other explicit users interactions are required.
In the Evaluation phase, with the federated model trained, the participants can evaluate the performance of the model with their own local (private) data. They can also apply new data on the model to do inference.
Hierarchy of meta-data required
Let's take a look at the meta-data the users need to supply in the Registration phase. Orchestrators and participants provide different information.
The meta-data that orchestrators have to supply to Synergos is organized into a hierarchy of collaboration, project, experiment, and run.
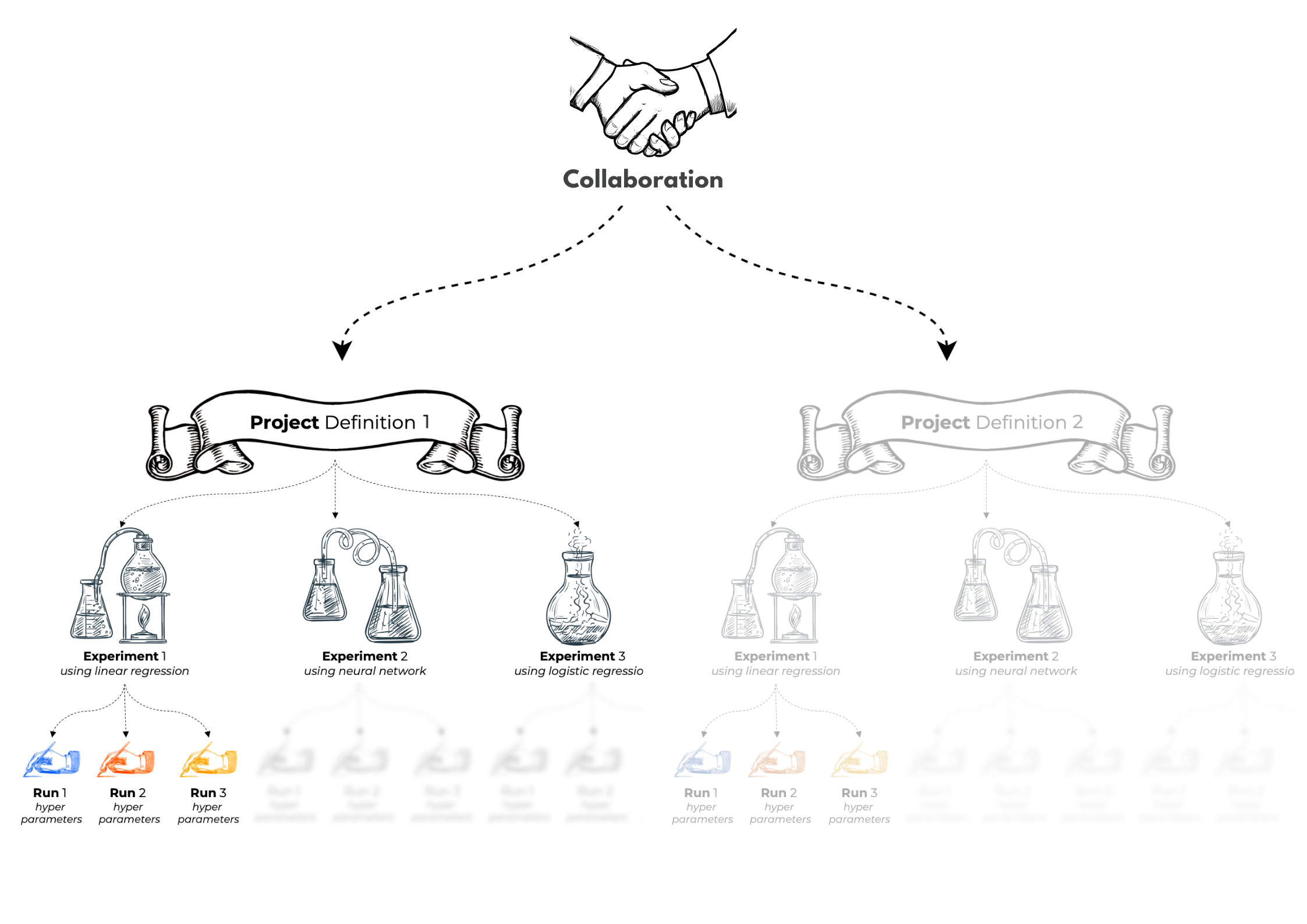
A collaboration defines a coalition of parties agreeing to work together for a common goal (or problem statement). Conceptually, a collaboration comprises only one orchestrator.
Within a collaboration, there may be multiple projects. Each project corresponds to a collection of data different parties in the collaboration use. If there is any change in the data they are using, a new project should be defined.
Under a project, there may be multiple experiments. Each experiment corresponds to one particular type of model to be trained, e.g. logistic regression, neural network, etc.
There are multiple runs under each experiment. Each run uses a different set of hyper-parameters.
Let’s use an example to better understand the relationship among different information in the hierarchy. When multiple banks decide to work together to build an anti-money laundering solution, they form a collaboration. Within this collaboration, those banks agree that each of them would use a set of local tabular data with a common schema, thus forming a project. Under this project, logistic regression is selected as one type of model to be built. So an experiment will be defined to train a logistic regression model. Assuming, regularized logistic regression is used, multiple runs will be defined with different values of the hyper-parameter 𝛌. Under the same project, if a neural network model of a different architecture is required, another experiment is created, which subsequently has a number of runs with respective hyper-parameters.
If there is any change to the agreed data (e.g. change in the common schema or some parties decided to use different rows of data), a new project will be defined.
After the orchestrator supplies all the necessary meta-data, those participants who agrees to join the collaboration, will then supply their meta-data too. First, they need to register their agreement to join the collaboration. And then they register the compute resources and data they are using for the respective projects. In this phase, they need to register the data used for their local training before the Training phase starts. They can also register the data used to do model evaluation in this phase. Another alternative is to register the data to do model evaluation or prediction/inference in the Evaluation phase.
What happens behind the scene to enable Federated Learning
The key to enable Federated Learning in Synergos is its Federation and Federated Grid blocks. Let's take a closer look
Federation and Federated Grid block are developed on top of PySyft, a Python library for secure and private Deep Learning developed by OpenMined, an open-source community actively promoting the adoption of privacy-preserving AI technologies.
PointerTensor
The main vehicle used by PySyft to make data “private” is its PointerTensor. As its name implies, it creates an abstracted reference pointing to remote data. And this reference can be used by a third party to execute computations on the data without actually “seeing” the data.
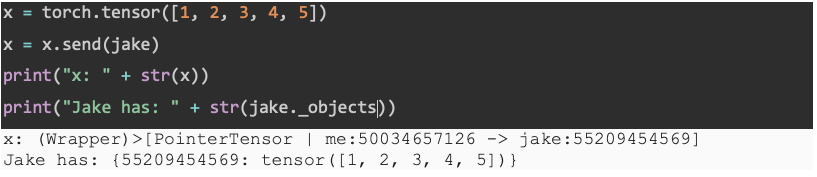
In this example, Jake is a Worker in PySyft. When we send a tensor to Jake, we are returned a pointer to that tensor. All the operations will be executed with this pointer. This pointer holds information about the data present on another machine. Now, x is a PointerTensor and it can be used to execute commands remotely on Jake’s data. An analogy to better understand PointerTensor is that it works like a remote control, i.e. we can use it to control a TV without physically touching the TV.
Federated grid
The PointerTensor is a powerful tool in making the data “private”. Nevertheless, it is at such a low level of abstraction, it is mandatory for developers to write their own coordination code before PointerTensor becomes operationally usable. And this is where federation grid comes in to help.
The Federation block defines the application level protocol over WebSocket to form federated grids. In Federation, parties who agree to work together would form a federated grid. A federated grid is a star-architecture network, in which different parties exchange messages among themselves to complete the model training and inference. The messages among different parties are exchanged via WebSocket protocol. The Federation block also exposes a number of REST APIs, which can be used to send commands to the federated grid, e.g. start the training, destroy the various workers when federated training completes, etc.
Workers and TTP
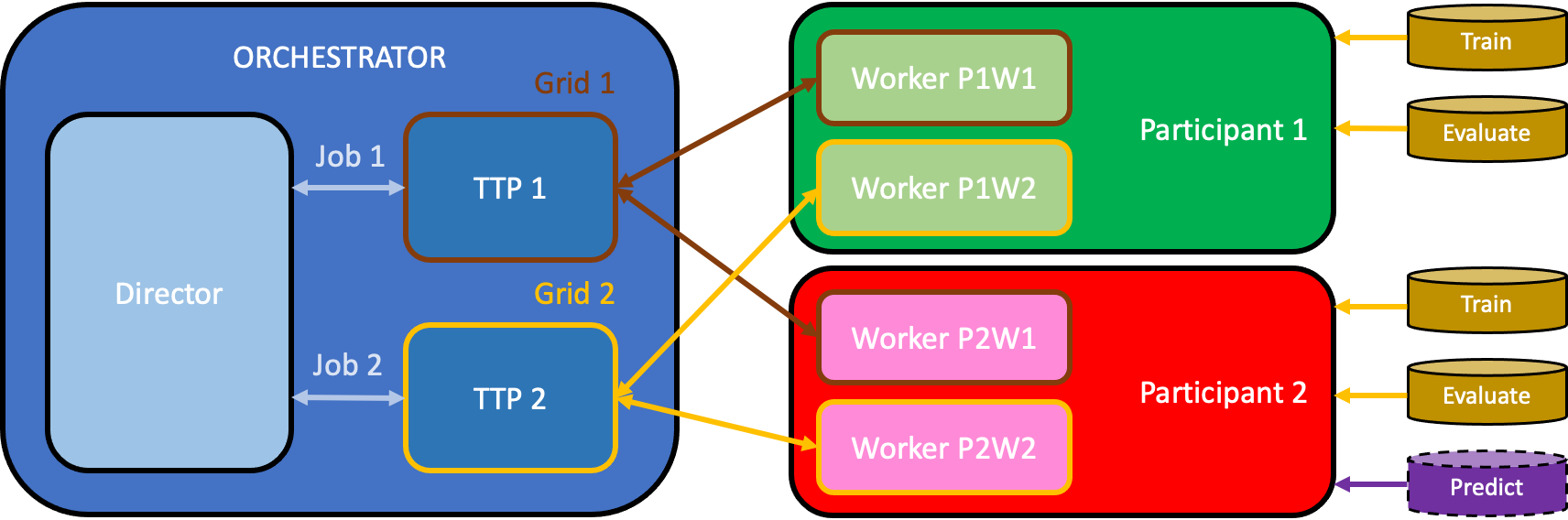
There are two main types of roles in a federated grid. The first role is the worker. Typically, each participant runs a worker (who instantiates Synergos Worker component in the Federation block). Individual workers do not expose their data to other workers, but only pass pointer to their data to the TTP or Trusted Third Party, which is at the centre of the star architecture. The TTP (which is run by the orchestrator who instantiates the Synergos TTP component in the Federation block) contributes no data, but it is the “remote controller” to the data of the workers'. Within one federated grid, there is one TTP. TTP coordinates with multiple workers in the same grid to complete the federated training.
Depending on the configuration of Synergos that is running (e.g., Synergos Cluster), there may be multiple grids running at the same time. In such configuration, the orchestrator may be running multiple TTPs, and each participant can also be running multiple workers, where each of them joins a different grid. Additionally, a third role, director (who instantiates Synergos Director component in the Orchestration block), is required to orchestrate multiple TTPs, who subsequently coordinates with the workers within their respective grids.
The diagram below illustrates all the different roles which enables Federated Learning.
What happens in different phases
With all the concepts and roles explained above, now, let's take a look of what happen behind the scene in different phases.
Registration
The Registration phase is for all the parties (both orchestrator and participants) to provide necessary meta-data. The orchestrator provides definition about collaboration, project, experiment, and run.
If a participant agrees to work with others, it registers its participation in the collaboration, defined by the orchestrator. The participant then declares the compute resources and data they are using. The connection information of the compute is used by TTP to establish the grid connection. Data is registered in the form of data tags (refer to this to see a guide on how to prepare data). All these information are stored and managed by the Meta-data Management block.
Training
After all the necessary meta-data have been collected, the orchestrator starts the training process. The guide below assumes the orchestrator is running Synergos TTP. Another guide with the orchestrator running Synergos Director is provided separately.
Upon receiving the instruction to start training, the federated grid has to be up and running before the federated training takes place. There are a few things happening to bring the grid up.
First, individual Synergos Workers are initialized. Each of them instantiates a PySyft WebsocketServerWorker (WSSW). The meta-data info supplied by the participants in the Registration phase is used by the TTP to poll their data tags for feature alignment. Feature alignment is a step to make sure different parties have the same number of features after applying one-hot encoding on the categorical features, without revealing the different participants’ data.
The TTP then conducts the feature alignment. The alignments obtained are then forwarded to the workers, which are used to generate the aligned datasets across all workers. The aligned dataset is then loaded into each worker’s WSSW when it is instantiated. It also opens up each worker's specified ports to listen for incoming WebSocket connections from the TTP.
Subsequently, for each worker, the TTP instantiates a PySyft WebsocketClientWorker(WSCW), which is to complete the TTP’s WebSocket handshake with the worker. When the handshake is established, the TTP’s WSCW can be used to control the behaviour of the worker’s WSSW without seeing the worker’s data. With this, a federated grid is established.
Now the federated training starts. The global model architecture is fetched from the experiment definition. Likewise, the registered hyper-parameters are fetched from the run definition. Pointers to training data are obtained by searching for all datasets tagged for training (i.e. "train" tag). During the training, TTP uses its WSCWs, which are connected to different workers’ WSSW, to coordinate the training, i.e. sending losses and gradients between TTP and workers to update the global model.
Once training is done, the final global and local models are exported. The federated grid will be dismantled. This is done by first destroying all WSCWs, closing all active WebSocket connections. The TTP then uses the connection information provided by the workers once more to send termination commands over via the REST API, which destroys their respective WSSWs and reclaims resources. Now the federated grid is dismantled, and training completes fully.
Evaluation
In this phase, it is mainly for the participants to evaluate the performance of the trained model with already-registered evaluation data or conduct inference with new data.
In this phase, the federated grid defined in the registration phase is recreated. Datasets with "evaluate" tag are retrieved from the federated grid. The global model is switched to evaluation mode (i.e. no weight update is happening), and is used to obtain inference results on the retrieved evaluation data across all participants. Once inference results are obtained, they are stored local at each worker. Subsequently, performance metrics are computed locally at each worker and sent back to the TTP for aggregation.
After these are completed, the federated grid is dismantled again with the same mechanism as described in the training phase.