Federated Aggregation Algorithms Implemented in Synergos
In conventional machine learning, it is commonly assumed that all data are independent and identically distributed (IID). In simple words, it assumes that all data are from the same generative process, and the generative process does not have memory of past generated data. However, in Federated Learning, as different parties do not see other parties’ data, it cannot be assumed that they all follow the same generative process. Special care is needed to address such non-IID data. Otherwise, the model derived with Federated Learning may not converge and generalise to different parties’ data, or simply take much longer to converge. Many federated aggregation algorithms have been proposed to address this problem.
Synergos makes Federated Learning accessible and user-friendly, taking away the burden from the users in implementing these federated aggregation algorithms. In Synergos, the Federation block implements a number of these algorithms. The most basic one is FedAvg. Besides this, the current version of Synergos also supports more advanced aggregation algorithms, including FedProx, FedGKT, etc. More aggregation algorithms will be supported in future versions.
FedAvg and FedProx
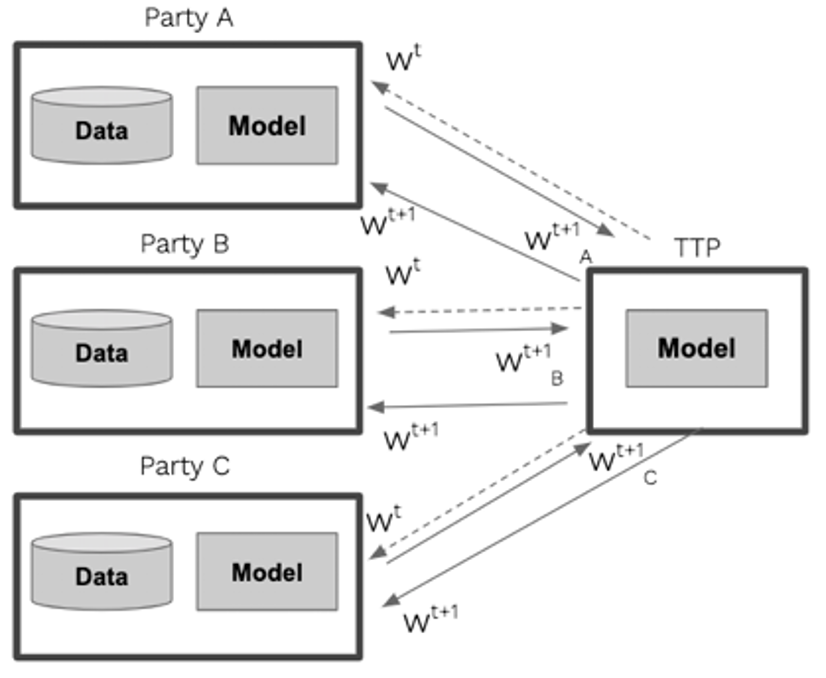
FedAvg is usually seen as the most basic version of a federated aggregation algorithm. In FedAvg, different parties train a global model collectively, with a trusted third party (TTP) coordinating the training across different parties.
At each global training round t, a global model is sent to all parties. Each party performs local training on their own dataset, typically using mini-batch gradient descent, for E local epochs with B mini-batch size. After every E local epoch, each party sends the parameters from its most recently obtained model state to the TTP. The TTP then updates the global model by conducting a weighted average of the parameters received from multiple parties, with individual parties’ weights proportional to their number of records used in the local training. This process iterates until the global model converges or a prefixed number of global training rounds is reached. The diagram below gives a simplified illustration of the FedAvg aggregation process.
FedProx uses a similar aggregation mechanism as FedAvg does. One key improvement which FedProx has over FedAvg, is that it introduces an additional proximal term to the local training, which essentially restricts the local updates to be closer to the latest global model, which helps the federated training to converge faster.
FedGKT
Another algorithm implemented is FedGKT (Federated Group Knowledge Transfer). It was originally proposed to allow low-compute federated training of big models with millions of parameters (e.g., ResNet 101, VGG 16/19, Inception, etc.) on resource-constrained edge devices (e.g., Raspberry Pi, Jetson Nano, etc.). The diagram (adapted from original FedGKT paper) below illustrates the training process of FedGKT.
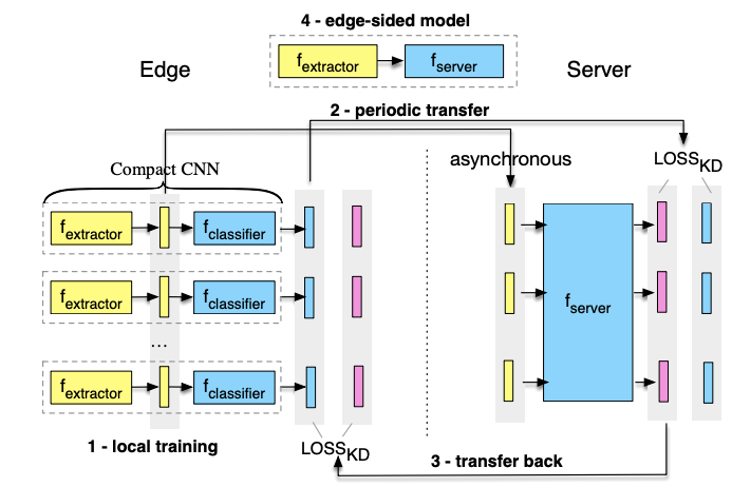
Essentially, there is one model in FedGKT, but split into two sub-models, i.e. each participating party trains a compact local model (called A); and the server (in our case TTP) trains a larger sub-model (called B). Model A on each party consists of a feature extractor and a classifier, which is trained with the party’s local data only (called local training).
After local training, all participating parties generate the same dimensions of output from the feature extractor, which are fed as input to model B at the TTP. The TTP then conducts further training of B by minimizing the gap between the ground truth and the soft labels (probabilistic predictions) from the classifier of A.
When TTP finishes its training of B, it sends its predicted soft labels back to the participating parties, who further train the classifier of A with only local data. The training also tries to minimize the gap between the ground truth and the soft labels predicted by B. The process iterates multiple rounds until the model converges.
When the training finishes, the final model is a stacked combination of local feature extractor and the shared model B.
One of the main benefits of FedGKT is that it enables edge devices to train large CNN models since the heavy compute is effectively shifted to the TTP, who usually has more compute power. Another benefit is model customization, given that different participating parties would have different local feature extractors which will be combined with the shared model B.
More algorithms will be supported in future version of Synergos.